






Today’s enterprises are storing roughly double the amount of data every two years from before, and are using it for a variety of workloads such as test and development, file shares, analytics, backup, cloud archival, etc. With needs for performance and capacity growing exponentially, enterprise data tends to get silo’ed into multiple storage products, which end up storing the data as multiple copies, replicated and uncompressed. These redundancies can easily be 10-20x more than the actual capacity needed. Providing that kind of storage requires large investments not just on the storage side, but in the overall IT infrastructure, such as networking, archival, cloud bandwidth, manageability etc. Thus, there are significant cost advantages in reducing the data footprint.
Traditional vendors typically employ some level of data reduction like compression or deduplication, but leave many opportunities behind when the system becomes complex.
To be able to reduce petabytes of data, we take the lock, stock and barrel approach:
- Hyperconverged platform that scales out in performance and capacity to unify all your secondary data silos and workloads onto a single platform, thereby eliminating the need to move data around for different use cases like backup, test and dev or analytics.
- Eliminate the need for multiple copies of the same files by providing copy data management using zero-cost snapshots and infinite clones.
- Provide global data deduplication across the scale-out platform, that can deduplicate small variable-length blocks of data.
- Compress the unique deduplicated blocks further down.
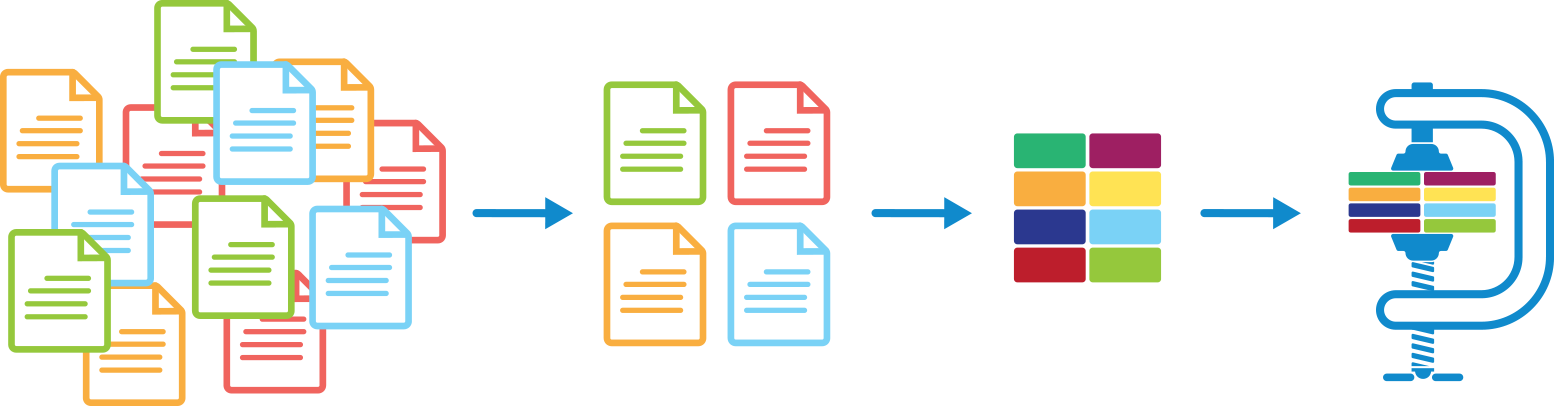
Let’s talk about these in more detail …
Hyperconverged Storage Platform
As I mentioned earlier, traditional IT infrastructure is deployed in silos for different use cases. This is done because their storage platforms cannot scale both in performance and capacity, or become prohibitively expensive in doing so. The enterprise thus might have several data silos as stages of data from hot to cold.
The Cohesity platform has been built as a hyperconverged scale-out platform. More nodes can be added to linearly scale the capacity and performance at a linear cost. It includes compute, memory, flash and deep storage in a single distributed file system that allows for different workloads to all work and co-exist. By leveraging this scale out platform, customers are able to consolidate their secondary data and workloads. Thus eliminating the need to keep multiple copies and move the data around between silos.
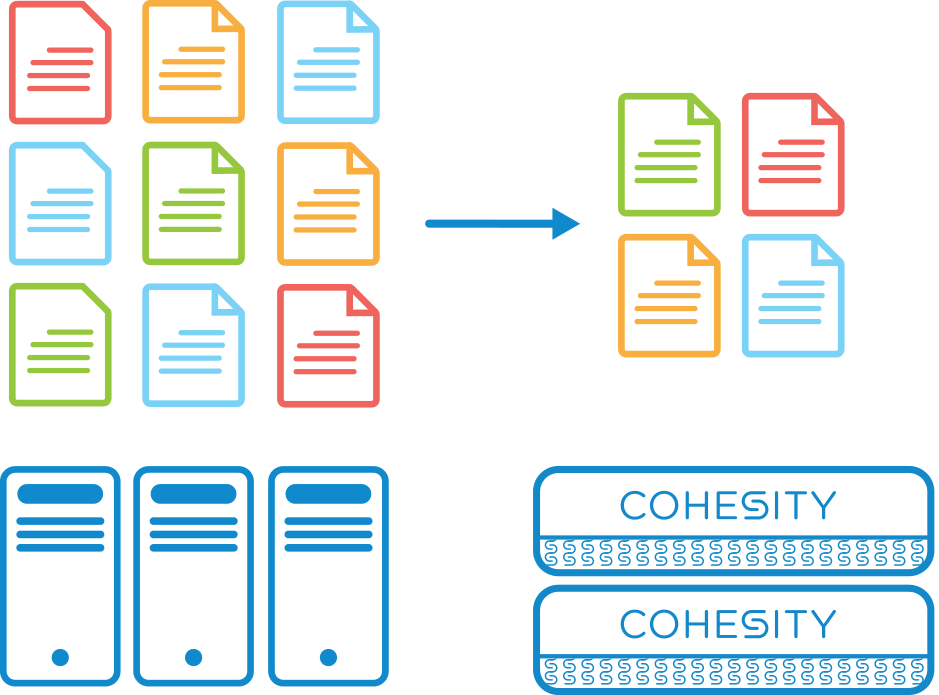
Cohesity and the Cloud
The platform also supports attaching cloud storage as an extra storage tier. This automatically extends the data reduction strategies also to the cloud, which helps bring down cloud storage and networking costs. Note that this data is also encrypted before being sent to the cloud.
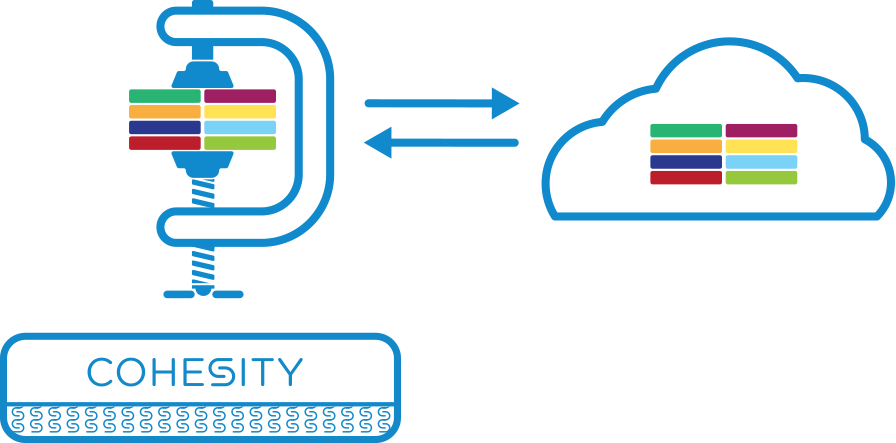
Copy Data Management
A recent IDC survey suggests that 60% of the enterprise storage is used for copy data! This copy data sprawl is driven by the lack of a single system to consolidate secondary data.
Cohesity begins with being the file server or backup target for your primary data. Once the data resides in the Cohesity platform, it provides copy data management to make copies available for other uses. Cohesity provides a zero-copy snapshotting capability, that can snapshot your files, directories or entire filesystems into new copies. These copies are based on a redirect-on-write architecture. Each copy only consumes the space required to store the changes to that specific copy. The Cohesity snapshots also carry no performance overhead, meaning that the snapshots can be taken as frequently as you want, and don’t have a performance penalty.
Also, being a hyperconverged platform, that utilizes flash, disk and cloud tiers, you get the low latencies, as well as scalable performance and capacity.
Global Deduplication
Deduplication is the technology where duplicate blocks of data present in multiple files are identified and only the unique blocks are stored. This task relies on having a metadata database that stores fingerprints of the unique blocks, for the comparisons. The deduplication task becomes quickly non-trivial when systems becomes large and complex. The metadata alone could go into terabytes, and hence can’t be handled by a single node. Also, it taxes the system resources as incoming data has to be parsed and compared with all the existing blocks.
These issues force storage vendors to:
- Employ deduplication locally per node, a.k.a. local dedup
- Use fixed size blocks
- Or use large block sizes
- Support only inline deduplication
All the above provide far less actual deduplication!
The Cohesity storage platform was designed from ground up to provide a powerful and flexible global deduplication architecture.
It has the following features:
- The block fingerprint metadata is shared across all nodes and they balance the load evenly amongst them.
- We use small variable length block sizes, that provide superior deduplication.
- And, we provide option to do post process or inline deduplication when needed.
Post-process deduplication allows users to write the data bypassing the deduplication logic; the deduplication is done at a later time when the data has become cold.
Also note that compression works well on a single file, but across files, there is a need for some macro level data compression. For example, when two identical copies of a file are stored, compression can individually compress the files, but deduplication can completely eliminate the need to store any data for the second copy. You can still compress the remaining blocks to further reduce the data size.
Compression
Having done data reduction at file level and block level, we get to the lowest level of reduction. Compression works by finding small byte patterns common between the deduplicated blocks, to further reduce the data footprint. Based on the type of data being ingested, compression can give no benefit for encrypted/random data, to 5-10x compression for log files. VMs, databases, file shares all lie somewhere in between that range. Note, that this is on top of the deduplication process discussed before.
We support multiple compression algorithms that are suitable for cold data as well as streaming data. Compression of the latter dataset can be done in order of several GB/s. Compression can be stressful on the system and clients can get some performance hit from it. However, if the data is compressible, then the benefit of reading and processing less data actually improves the performance by a good margin, which becomes a win-win situation.
Customers can choose which datasets should be compressed, and whether they want data to be compressed while it’s being written inline or at a later stage.
Conclusion
In this blog I touched on the 4 aspects of data reduction, that provide critical techniques to reduce the data usage as much as possible. The challenge that Cohesity solves is that it does them in a flexible, generic and optimal manner, on a massively scalable storage infrastructure. As an example customer real-world use case, let’s take the example below.
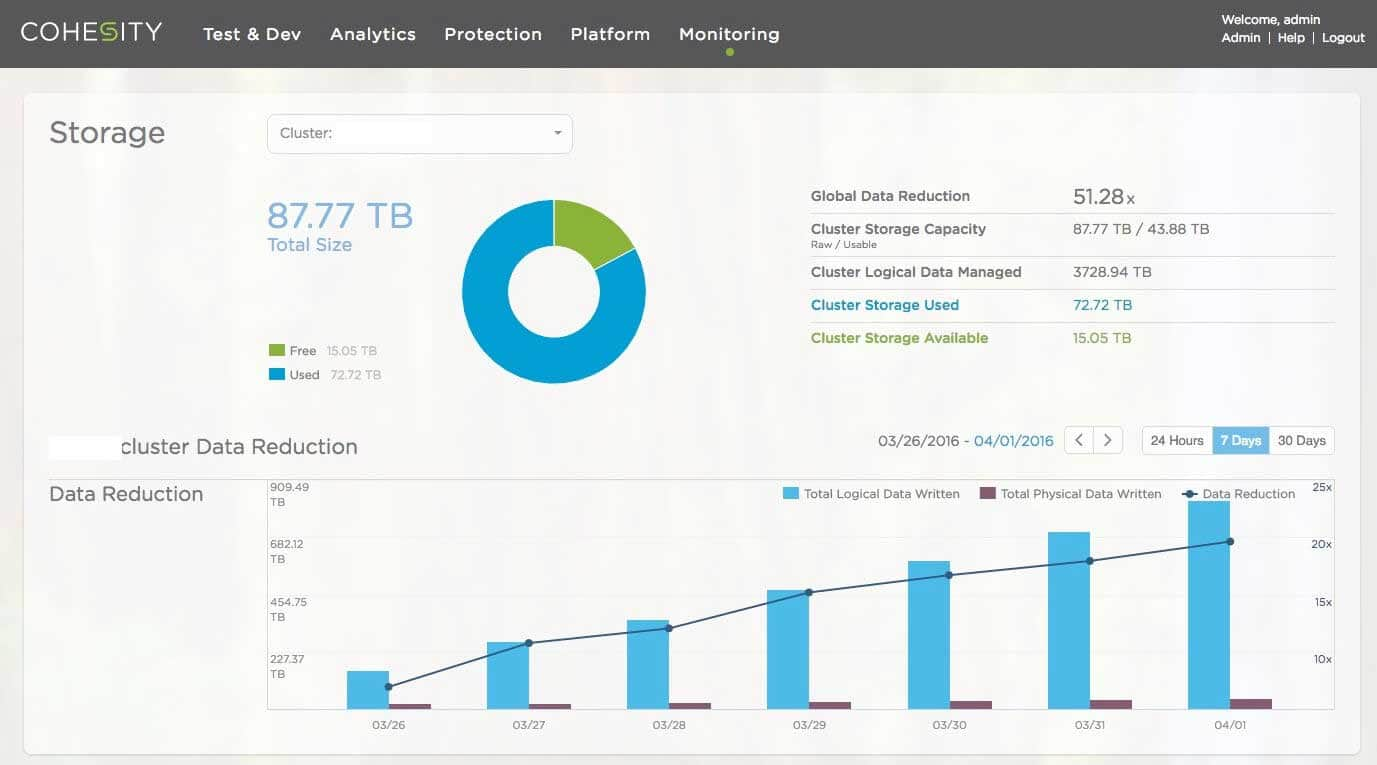
The customer is storing VM backups, file shares and home directories here. As they store more data on the cluster (blue bar), the physical usage is growing at a much smaller rate. All the data reduction techniques are working to make sure the initial and incremental data additions all get reduced as much as possible. Eventually after they wrote 3.7 PB of data, the physical usage still remained at 72 TB!
This kind of capability to reduce data can be transformational to a company from the perspective of staffing, technical ability, and massive reduction of datacenter footprint required to store this amount of data, and we’re seeing it transform the way our customers do business every day!








