






At Cohesity, we are on a mission to redefine secondary storage. We believe that legacy storage solutions such as traditional dedupe appliances, backup software, and NAS can’t keep up with the needs of the modern enterprise. Enterprises must manage rapidly increasing data volumes – projected to increase from 6 Zettabytes in 2016 to 93 Zettabytes by 2025, according to IDC. Enterprises are also going multicloud, and must make data readily available across cloud environments for recovery, test/dev and analytics.
To solve these enterprise challenges, Cohesity pioneered the concept of Hyperconverged Secondary Storage, which enables enterprises to:
- Consolidate all secondary storage on one web-scale platform, including backups, files and objects
- Deliver data instantly for recovery, test/dev and analytics
- Manage data across multicloud environments
But we couldn’t deliver on the vision of Hyperconverged Secondary Storage with aging, legacy file systems. Legacy file systems were optimized around just one use case, such as variable-length inline dedupe for backup targets.
To break down legacy storage silos, Cohesity had to build a completely new file system: SpanFS. SpanFS is designed to effectively consolidate and manage all secondary data, including backups, files, objects, test/dev, and analytics data, on a web-scale platform.
SpanFS is the only file system in the industry that simultaneously provides NFS, SMB and S3 interfaces, global deduplication, and unlimited snaps and clones, on a web-scale platform. And it provides native integration with the public cloud to support a multicloud data fabric, enabling enterprises to send data to the cloud for archival or more advanced use cases like disaster recovery, test/dev and analytics. All of this is done on a web-scale architecture to manage the ever-increasing volumes of data effectively.
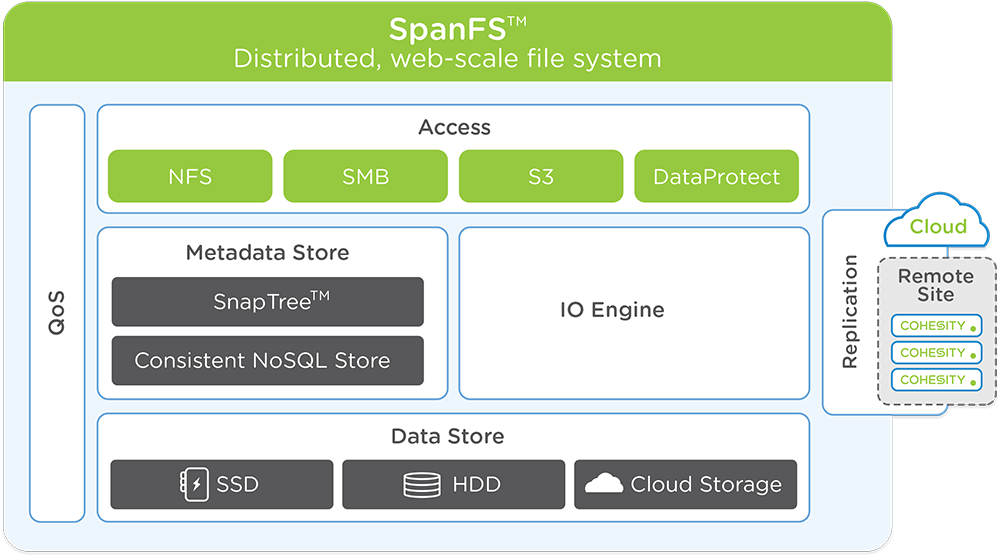
Let’s take a closer look at the architecture of SpanFS and how it’s fundamentally different from legacy file systems. At the topmost layer, SpanFS exposes industry-standard, globally distributed NFS, SMB, and S3 interfaces. Underneath the access protocols, the IO Engine manages IO operations for all the data written to or read from the system. It detects random vs. sequential IO profiles, splits the data into chunks, performs deduplication, and directs the data to the most appropriate storage tier (SSD, HDD, cloud storage) based on the IO profile. To keep track of the data sitting across nodes, Cohesity also had to build a completely new metadata store. The metadata store incorporates a consistent, distributed NoSQL store for fast IO operations at scale, and SnapTree provides a distributed metadata structure based on B+ tree concepts. SnapTree is unique in its ability to support unlimited, frequent snapshots with no performance degradation. SpanFS has QoS controls built at all layers of the stack to support workload and tenant-based QoS. It can also replicate, archive and tier data to another Cohesity cluster or to the cloud.
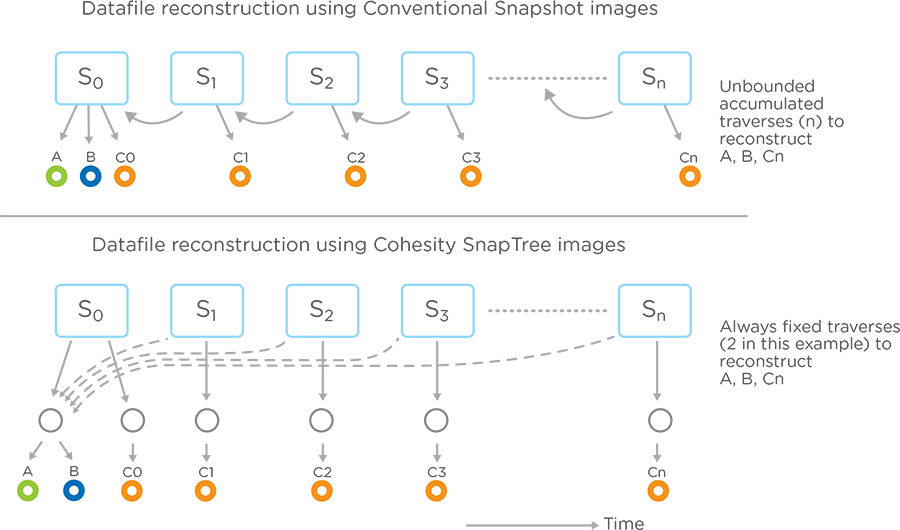
SnapTree introduces a completely new approach to managing metadata at scale. In legacy storage, snapshots form a linked chain, with each link containing the changes from the prior snapshot. Every time a new snapshot is done, an additional link is added to the chain and adds performance overhead.
To provide unlimited snapshots and clones at web scale, SnapTree manages metadata with a B+ tree metadata structure, but adds multiple innovations including:
- Distributes the tree across nodes
- Provides concurrent access from multiple nodes
- Supports the creation of instantaneous clones and snaps
With SnapTree, Views (volumes) and files are represented by a tree of pointers to the underlying data. The root node represents the View or individual files. The root node points to some intermediary nodes, which in turn point to the leaf nodes which contain the location of the chunks of data. Customers can take snapshots of entire Views (volumes) or individual files within the Views. As snapshots are taken, the number of hops from the root to the leaves does not increase. Customers can take snapshots as frequently as desired – without ever experiencing performance degradations.
SpanFS and SnapTree together provide a unique file system designed specifically for secondary storage consolidation. This is the technical foundation that makes Hyperconverged Secondary Storage possible. And allows you to take back control of your data.
To learn more about SpanFS and SnapTree:








