






When people hear “object storage,” there is a tendency to dismiss it for some reason, in some form of “I don’t need that [yet]” or “I don’t understand it, so I’m going to walk away and dismiss it.”
Unfortunately, this sort of action can stymie adoption of newer technology. Those of us that were implementing ESX in the 2.5 and 3.0 timeframe, circa 2007, ran into this quite a bit.
Recently, a lot of the talks I’ve been giving have required starting with a certain level of education around what makes distributed storage different, how it directly relates to object storage, and how you essentially have to let go of a lot of the storage fundamentals that have been ingrained into your minds and thought processes over the last couple of decades.
1. Goodbye RAID. Hello RAIN.
Oh, RAID. Dear, dear RAID. We’ve all used it in one way, shape, or form. Sometimes not even realizing we were using it. In case you’re unaware, it stands for Redundant Array of Independent Disks. There are many different configurations that have evolved over the years… RAID-0, RAID-1, RAID-5, RAID-6, RAID-DP (NetApp), RAID-3D (Pure), and yes, the always glorious and expensive waste of money known as RAID-10.
At the most core fundamentals of all-things storage are the disks themselves and how they’re assembled underneath a storageOS. EMC uses Disk Pools, NetApp aggregates. Even within those NetApp aggregates, there is an additional hidden layer of a “raid group” that many users are still, to this day, grossly unaware of, and how it directly impacts their performance. I would wager it’s still one of the top support calls to solve performance troubleshooting issues (undersized raid groups. 14+2 folks!)
Other vendors also have their own flavors of this sort of thing. Bottom line, this is a trademark of the traditional/legacy/pick-your-adjective storage architecture, and it’s time for it to go away once and for all.
RAIN, on the other hand, is a similar concept, but stands for Redundant Array of Independent Nodes. In node-based architectures, there are indeed storage mediums, such as hard drives, PCIe Flash Cards, etc, but they are viewed simply as consumable resources within the cluster. Instead of piling hard drives into raid groups, you set a collection of nodes into a cluster, and lay a distributed file system on top of it to commoditize and consolidate all available resources into a single pool. A particular subcomponent of the file system will handle reads and writes, and all other additional storage services, while providing an inherent level of fault tolerance by writing to multiple nodes in the cluster, and not having to keep entire hard drives set aside for things such as parity and spares.
There also seems to be a common misconception that all distributed systems are “eventually consistent.” For the purposes of giant cloud-based object stores, this understanding that a transaction in Chicago will eventually update in the Seattle datacenter makes sense. However, when dealing with enterprise workloads on top of object storage, this simply is not good enough, and a more strong consistency within the cluster itself needs to be leveraged. This is one of many pieces that makes the all-new Cohesity OASIS platform unique.
2. No more Volumes & LUNs.
After we eliminate the need to manage discrete hardware components like hard drives, we can begin to look at the items we’ve come to expect to live within these pools of drives: Volumes and LUNs.
While some of the fundamental concepts of these containers persist to distributed systems, the items themselves directly go away. Presentation of an interface for interaction with a host/client is all that is required, and the subcomponents of the file system maintain the data underneath without the need to hard-carve out a space for your data to live.
More on this when we get deeper into object storage below…
3. Don’t be scared of object storage. You need it.
We need to start talking seriously about object storage, and we need to do so until it becomes a household name outside of the context of AWS S3 interfaces.
Here’s the skinny… know how we spend so much time talking about blocks and files? Ask any storage guy, and even today’s virt and sys admins, and they can explain to you fixed and variable block size, thick vs thin provisioning, and change rates/deltas. All things related to traditional storage architectures based on blocks and files.
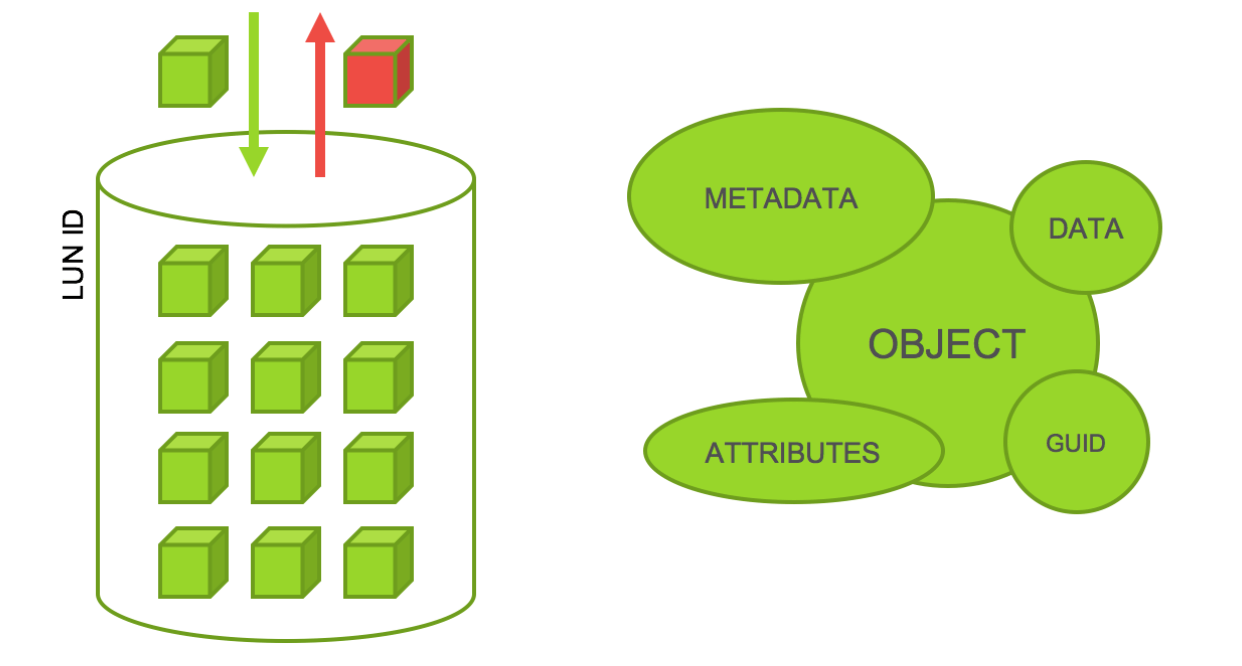
But that’s just the thing… enough of all this bickering about which block size is superior to another, and whether or not block is better than file, SAN better than NAS, etc etc, ad nauseum.
The answer is hidden beneath the things we use everyday… Amazon, Facebook, Google… all operations sitting on top of giant object stores.
4. Index all the things.
What’s the most powerful service each of those platforms above provide? Search!
Imagine empowering your enterprise with a distributed filesystem of like capability, enabling you and your teams to leverage wildcard and predictive search across all of your data. This is the sheer power of indexing.
When all writes come into a distributed system, every object is indexed, and as far as the system is concerned, an object is an object is an object. Regardless of whether it’s an MP3 file, an Excel spreadsheet, a VMDK, or a file on the windows desktop of a guestOS within a virtual machine, it becomes an eventual searchable result.
Putting analytics aside for a moment, just the ability to quickly search for *.VMDK across your entire secondary storage footprint, and to get an immediate response to be able to act upon that result is something that we haven’t quite seen in the mainstream enterprise to-date. But I tell you what, as soon as you get your hands on it, you’ll wonder why you haven’t had it the whole time.
This is the power of object storage, folks! BUT WAIT…. there’s more ….
5. In-place analytics changes everything.
Not only does indexing unlock and empower you with your own search engine, but now that we’ve got all this data, with heaps of metadata to go along with it, what else can we do with it?!
Folks, this is the primary reason I joined Cohesity, because of this very thing. Sure, backup is cool, and there’s a nice new approach to simplify it, and yes SnapTree’s rock and can be an efficiency game-changer within your DevOps workflows, but let me tell you…
Before we get too deep into the custom analytics stuff, let’s talk about the default reports that come to you out of the box. Discrete analytics about your storage utilization by user, VM, file type, etc. Backup job run reports, VMs not being backed up, the list goes on. These are all delivered to you FOR FREE as part of OASIS, and can be run by you manually, or scheduled to run at any time. This alone is huge, as most of these kinds of reports require 3rd party software to analyze your storage systems separately and generate reports.
Our native reporting capabilities on our system are simply unmatched. Reflecting on my time as a datacenter engineer for a big healthcare company, I would have done anything to have had these kinds of reports to simply spin out and hand to auditors when they visited every six months.
Taking it one step further, our in-place analytics capabilities do not stop there. Not only do we provide a laundry list of reports that you’ll find incredibly useful, but remember that part about how we index everything that comes onto the box? Well, that’s not just for search results for you to perform restores and clones.
We call it Analytics Workbench (AWB).
Imagine having your very own little App Store within your enterprise storage system. This is not your typical app store in the sense you’re thinking about, with delivering apps to mobile devices. This is applications in the context of a sort of repository of Custom and Saved Searches, IF-THEN-ELSE workflows that do Pattern-matching for search-strings while performing a completely distributed GREP across your entire cluster and then act upon, even so far as being run on a schedule.
Example, you ask? Well, scan all files across the entire cluster for a pattern matching \d\d\d-\d\d-\d\d\d\d. Run this once per hour, and alert me if any is found with the filenames. If found, quarantine file to a particular Viewbox that is completely locked down and unable to be accessed from anyone with Admin privileges.
PHI/PII, eDiscovery, Threat Analysis, and Anonymization are just a few of the use-cases we’re talking about here. The opportunities are endless, and we haven’t even talked about the HDFS+ we can expose from our system to extend our MapReduce and indexes to an existing Hadoop cluster.
6. Data consolidation is key.
Think back for a second. Can you rattle off three of the core, fundamental reasons we consolidated all of our servers with virtualization?
Here, I’ll go first…
Underutilization of resources, complex management and tracking of physical entities, limited rackspace and power/cooling, expensive licensing models, sprawl and lost tracking of resources.
What I will share with you is that many of the fundamental reasons to do the exact same thing with your secondary storage are no different. Your storage systems are either underpowered or being underutilized, you’re probably tracking a multitude of physical resources and licensing from many different vendors, and managing them all with different UI’s, all of those controllers and disk shelves have taken over your datacenter footprint, replacing the piles of servers we had 10 years ago. VMware didn’t exactly save the day with licensing (spoiler: it’s expensive!), but it did help optimize Enterprise ELA’s from Microsoft by leveraging a lower cost server license (Datacenter). And while it did help consolidate a lot of the servers initially via P2Vs, it seemingly only perpetuated the issue of “sprawl” now that VMs were “free” in the eyes of the end users.
My point here is, look, we’ve been through this before! We’ve learned a LOT of valuable lessons from the server virtualization, and even throughout the early stages of the cloud era. There are reasons we virtualized in the first place. There are reasons enterprises are looking to the public cloud to offload a lot of their storage needs initially, if not entire workloads. We could spend a whole post talking about that. In fact, I talked about it here: Welcome to the Data Consolidation Era.
7. Open source has single-handedly evolved the industry.
I didn’t want to get through this post without mentioning two very important things.
Open Source has absolutely changed our industry. One of my favorite blogs to read over the last decade-ish has been the techblog.netflix.com of Netflix. Those fine folks, in my opinion, invented a lot of the things we take for granted today on how to properly run mega-scale in the cloud, and then you know what they did? They open-sourced the code so everyone else could use it as well. Almost every component that makes Netflix’s infrastructure amazing is available for you and your enterprise to use. This is also true for companies like Facebook, Amazon, Google, and many more.
My point here is, these companies were the pioneers of webscale object storage, et al, and they all freely and openly contribute the code to the greater industry and community. With their contributions, almost anyone can come in and stitch together some open source code on an x86 box and make a storage system. I find this as encouraging for our industry as I do a cautionary tale that I’ll share with you. Be wary and be vigilant when taking a look at your next purchase from a vendor claiming they can do what they can do, and I hold Cohesity to no different standard. Ask the hard questions, do your due diligence, make them prove it. It’s not always about price. For example, if a vendor says they can do Global Reduplication, make them define their version of Global.
8. Move compute to data, not vice versa.
We received a lot of feedback at Storage Field Day 8 about just how much compute power there was in relation to the amount of storage in one of our fully-populated chassis. Well, hopefully now at the end of this post, you can see why, especially when you’re performing all of the table-stakes storage services, including Dedupe, Compression, Encryption, etc all on the same box, AND leaving enough overhead to handle generic disk operations, AND doing deep analysis of your data within AWB. The box was intentionally built to be a workhorse.
Hardware at this point has been completely commoditized. It does not even truly influence purchasing decisions anymore. So why not throw as much raw horsepower into each of the nodes as you possibly can while not murdering your COGS?! Prepare for the future! All of this is going to continue to evolve and grow year after year. Hell, Samsung says we’re gonna have 16TB 3D-NAND SSD’s next year. Stew on that for a minute while reflecting on the fact that we use the highest capacity 8TB helium-filled drives currently on the market.
Secondly, everyone seems to be obsessed with the phrase “moving to the cloud.” Well, that means moving terabytes, if not petabytes, of data. That’s no small feat, and can take days/weeks/months to do. I would challenge you to qualify to your partners and vendors what “moving to the cloud” means to you and your business, ultimately, and if it might be smarter to keep your data in one sovereign place while adding more compute and powerful software around it.
Distributed storage will be your salvation.
Object storage and distributed file systems are nothing to be scared of. I mostly blame the traditional storage vendors for their sloppy implementations (EMC Centerra, NetApp StorageGRID, etc) and lack of proper marketing to the enterprise, while the webscale cloud providers just leveraged it without you truly knowing about it.
So the enterprise has been left in the dark when it comes to object storage. Let’s change that. Let’s lift the veil and show everyone that it’s not so scary after all.
Is your company currently using any form of object storage or distributed file systems? If not, is it something you’re interested in but still meeting resistance? I would love to hear your hurdles and struggles!







