






Traditional backup and recovery solutions were designed for the monolithic applications of yesteryear, and are unable to offer the granularity required to backup and restore today’s cloud-native applications. For modern workloads – cloud-
native applications built using containers and managed by Kubernetes – a backup solution must cover disaster recovery scenarios, data migration use cases, and hydration of dev and test environments. These scenarios present unique challenges for backup and recovery of these cloud-native applications.
In this blog, I’ll explain how the data center has evolved from monolithic apps to cloud apps, and how these modern workloads have changed backup and recovery requirements for IT.
The advent of Kubernetes has made it practical to deploy and manage container infrastructure and thereby to deliver app services running in these containers. It has now become practical to develop and test code on a laptop and deploy it at scale anywhere—in any cloud or any infrastructure—thus abstracting away the entire OS and kernel level dependencies. But cloud-native application workloads have brought in considerable complexity to the life of an application administrator and DevOps teams that need to deploy and manage these applications.
Given the underlying complexity, as well as a need to manage state across disparate services that are globally distributed, backing up application data or preserving state information is not trivial. At the same time, the importance of backing up cloud apps is an increasingly critical area of focus for IT. Simply put: backing up cloud-native applications deployed by Kubernetes needs a new approach to ensure that applications survive disasters, are built to be resilient, and can have data migrated across cloud environments.
Cloud Native applications change from fully stateful to stateless applications
Application development has come a long way. Remember the days when an entire application was run within a server that ran the OS, had attached storage and memory, and was deployed in a single enterprise data center? Although data centers are increasingly run in the cloud, many legacy applications still exist and are still run in this manner. These applications are neither highly available, nor distributed or scalable to cater to a global client base.
These monolithic applications preserve state, manage dependencies, and work in a typical client-server model. Administrators perform periodic backups from time to time in order to protect against data loss or disaster. The goal is always to preserve the application so it can be recoverable to a previous known working state in case there are issues, such as a new software build that caused instability. Users are also known to corrupt the data store or the application by way of malware they inject into the application unintentionally.
In contrast, cloud-native architecture, formalized by the 12 factor app, provide a framework for building and delivering apps as a service brought together by a loosely coupled set of micro-services that together constitute an app. Apps architected in this so-called service oriented architecture (SOA), bring in unprecedented advantages to developers by way of rapid innovation, globally distributed delivery, horizontal scalability, and flexible deployment. Delivery of these modern application workloads was made practical by advances in cloud infrastructure that lend naturally to an agile development methodology in which the different components can be developed, deployed, upgraded, and maintained separately.
- Ephemeral vs. Persistent data
- Meeting SLAs
- App portability considerations
- Dev/test considerations
- Backup/Recovery still required
However, with the advent of modern workloads and containers comes the need for management. Modern applications that are delivered as a set of containers need to be orchestrated by a container management system such as Kubernetes (K8s). There are a set of stateless master and worker nodes that run code as well as stateful components that maintain and manage state and configuration. Stateful components include a central key value store database – such as etcd – that stores all K8s cluster configuration and state. Any changes to the K8s environment is reflected in etcd. Besides etcd, there are also persistent volumes where the application stores data, file system, and provider snapshots.
Stateless components are, in a sense, disposable infrastructure that can be turned up and down on demand. So, when there is a disaster that wipes out K8s clusters and master or worker nodes, the nodes themselves can be brought up easily. However, these nodes are like newborn children that wake up with no memory of where they came from or what they did the previous day.
Containers are ephemeral – data and state need backup
A recent survey by Sysdig indicates that more than 85% of all containers running today, die within a day and yet the data and state needs to be preserved in order to recover an application to working state. Such is the ephemeral nature of containers. This point drives home the need to have a robust backup of etcd, which in some sense is the central nervous system of the K8s deployment; it preserves the state of the infrastructure and the persistent volumes that contain the application data.
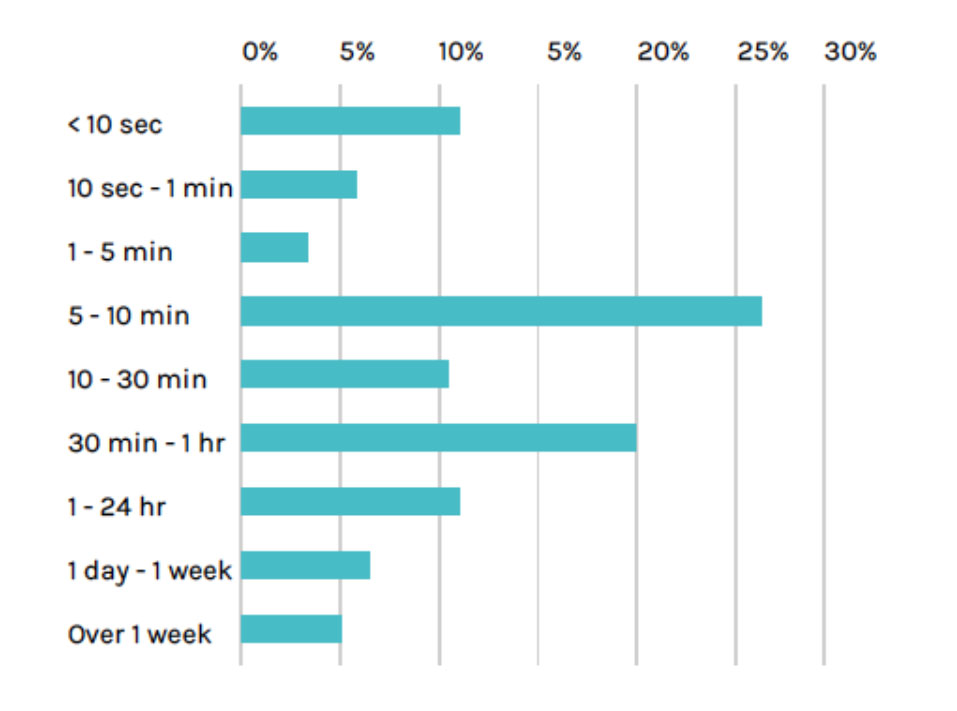
Source: Sysdig
Disaster recovery and backup for applications K8s
Entire K8s container environments need a robust disaster recovery and backup strategy that allows stateful and stateless components to be restored to a previous working state in the event of data loss or disaster. A robust disaster recovery and backup strategy is also needed when data is migrated, such as from one cloud provider to the other. It is also important to meet Service Level Agreements (SLAs), so the time it takes to recover clusters in K8s and restore state is a crucial consideration.
However there are other use cases such as data migration, archival, retention, and dev/test scenarios, in which a more granular backup and recovery is needed.
Take for instance the case of data migration from one cloud environment to the other. This is in the realm of possibility due to the abstraction provided by K8s and containers to the underlying infrastructure. In this case, the entire K8s environment may not be backed up and the entire etcd state need not be restored. There is a need to be granular, in order to be able to backup a specific namespace for instance, or exclude that namespace which should not be migrated. Here, the state information and application data for that namespace alone needs to be backed up. Additionally, there needs to be some flexibility on the restore operation if there are some changes needed due to the underlying differences in deployment architecture of the recovery infrastructure.
In the case of data protection, the application volumes may be corrupted due to an underlying cloud hardware failure or other reasons. The restore operation maybe on a single file. So, the level of granularity of the backup and restore operations is a critical consideration to be able to restore the cloud native application.
With any modern application development cycle, it is common to deploy and test applications in a sandbox environment that is separate and isolated from the production environment that runs applications and serves customers. In such environments, to get meaningful testing of the app before it is deployed, there is a need to hydrate dev and test environments with data so that applications can be tested in sandbox environments with real application data. In such cases, specific pods of containers or persistent volumes can be annotated for backup from a production environment to be restored into a test environment. As a result, there is a need for tagging specific components of the K8s infrastructure and being able to backup to a different type of environment.
Beyond recovery – security and vulnerability management
The above considerations that we covered get us to being able to backup and recover the various components of a modern application infrastructure. Once this is in place, regular snapshots can be taken and restored from. Depending on business needs and the nature of the application, the frequency of snapshots can grow rapidly. There is, as a result, the need to be able to search through the backups to figure out the right recovery point. This recovery point is most often tied to state, but also to SLA and other factors. Security could be one such factor.
DevOps teams have responsibility to ensure that application production environments are free from vulnerabilities. Before restoring from the chosen snapshot, DevOps teams need to be able to scan each restored component for vulnerabilities as the time between snapshotting and recovery could have brought in additional risks to the application environment.
In summary, we see how modern workloads—cloud-native applications that are architected, developed, and delivered differently from a monolithic application—need a fundamental rethink on how application data, system, and infrastructure state is backed up, snapshots searched, scanned and restored.
Read more about data protection for container apps based on Kubernetes here.








