On appelle classification des données le processus qui consiste à les catégoriser en fonction de leur sensibilité, de leur importance ou d'autres critères. Cette classification permet aux entreprises de gérer et de protéger plus efficacement leurs données en leur attribuant des niveaux de sécurité et des contrôles d'accès appropriés. La classification des données permet de s'assurer que les informations sensibles ou critiques sont suffisamment protégées, et que les données moins sensibles ne sont pas soumises à autant de restrictions.
Grosses annonces. Innovation audacieuse. Bientôt disponible.
Découvrez comment stimuler la résilience partout : dans l’IA, le cloud et l’identité.
Classification des données de Cohesity
Les données sont partout, et vos sauvegardes les rassemblent toutes. Cohesity vous donne de la visibilité, du contexte et du contrôle sur vos données sensibles. Vous pouvez ainsi minimiser les risques et accélérer votre réponse en cas de perte de données.

PRÉSENTATION
Identifiez la gravité d’une attaque
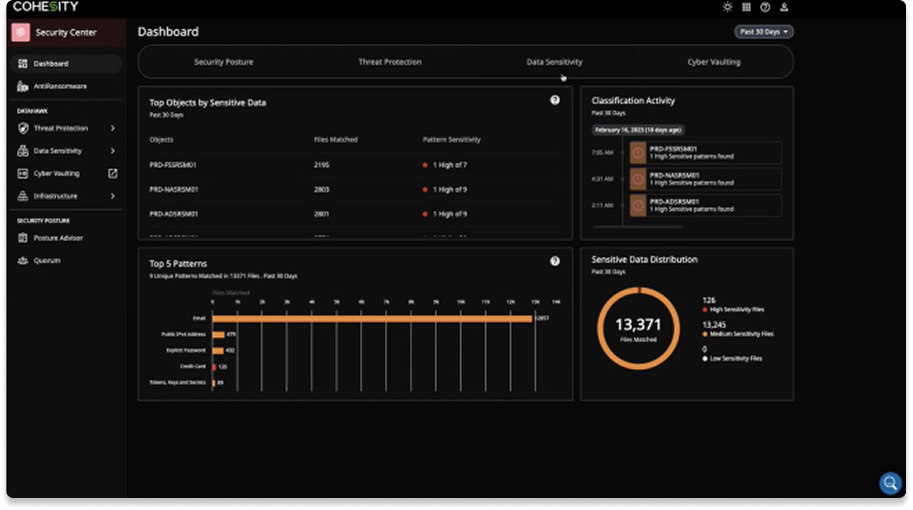
Savez-vous quelles données sensibles ont été affectées suite à une attaque par ransomware ? Classifiez les données sensibles, notamment les données à caractère personnel (DCP), à l’aide de notre moteur très précis basé sur le machine learning (ML). Comprenez comment les données sensibles prolifèrent, ou faites appel à la classification en cas d'anomalies pour analyser l'impact des données sensibles.
Fonctionnalités
Évaluez vos risques
Structurez la prolifération des données en identifiant les données sensibles, réglementées et précieuses, et réduisez le risque d'exposition des données aux cyberattaques ou aux menaces internes.
Accélérez votre mise en conformité
Classez les données personnelles, sensibles et réglementées pour pouvoir les mapper à des cadres tels que HIPAA, RGPD et PCI.
Comprenez l'impact des cyberattaques
Comprenez l'impact d'une cyberattaque sur votre entreprise en identifiant rapidement les données perdues ou volées afin de pouvoir hiérarchiser votre réponse.

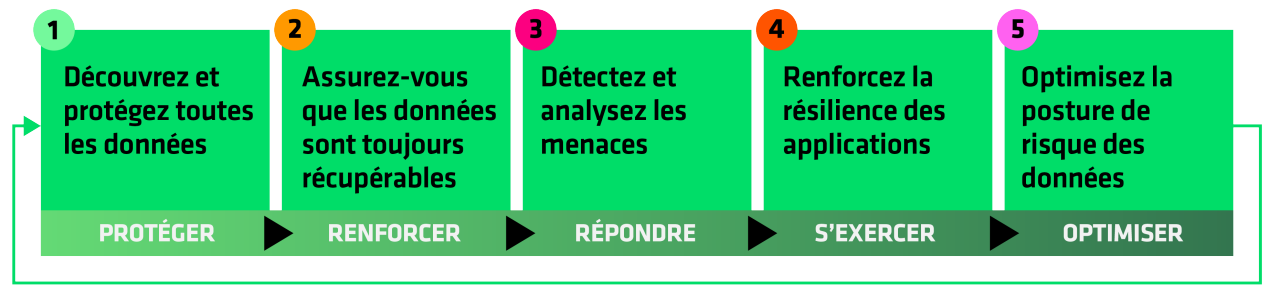
Les 5 étapes de la cyber-résilience définies par Cohesity©
Faites évoluer votre approche en vous appuyant sur l’expertise de Cohesity, afin de renforcer vos dispositifs de réponse aux cyberincidents et de consolider vos capacités de restauration et de reprise d’activité.

L’équipe CERT (Cyber Events Response Team) de Cohesity
Répondez plus rapidement et restaurez plus intelligemment, car votre entreprise ne peut pas se permettre de subir des temps d'arrêt.
- Temps d’arrêt et pertes de données minimisés : une réponse experte aux incidents avec des outils de restauration robustes réduit considérablement le risque de perte de données afin que votre entreprise puisse restaurer plus rapidement.
- Réponse rapide aux incidents : l’équipe CERT de Cohesity intervient immédiatement pour vous aider à limiter les dégâts et à lancer la restauration.
- Partenariats stratégiques : nous sommes partenaires des plus grandes entreprises de réponse aux incidents de cybersécurité afin que vous puissiez bénéficier de tous les outils nécessaires pour répondre aux cyberattaques.
Questions fréquentes sur la classification des données
La classification des données peut varier en fonction des besoins et des exigences spécifiques d’une entreprise. Les types de classification des données les plus courants sont toutefois les suivants :
1. Classification réglementaire : classe les données conformément aux exigences réglementaires. Par exemple, les données peuvent être classées comme des informations personnelles sensibles dans le cadre de réglementations telles que le RGPD (règlement général sur la protection des données), ou comme des informations de santé protégées en vertu de l’HIPAA (Health Insurance Portability and Accountability Act).
2. Classification en fonction de la confidentialité : elle est basée sur le niveau de confidentialité ou de sensibilité. Cette classification comprend généralement des catégories telles que public, usage interne uniquement, confidentiel et très confidentiel.
3. Classification en fonction de la criticité : les données peuvent être classées en fonction de leur caractère stratégique pour les opérations ou la mission de l’entreprise. Par exemple, les données critiques peuvent être des documents financiers, de la propriété intellectuelle ou des secrets commerciaux.
4. Classification en fonction de l’accessibilité : elle permet de classer les données en fonction de qui doit pouvoir y accéder. Par exemple, les données peuvent être classées comme accessibles à tous les employés, restreintes à des départements ou équipes spécifiques, ou limitées à certaines personnes disposant d’autorisations spécifiques.
5. Classification en fonction du cycle de vie : elle est basée sur le stade du cycle de vie, par exemple actif, archivé ou obsolète. Cette classification permet aux entreprises de gérer efficacement le stockage, la rétention et l'élimination des données.
6. Classification en fonction du format : elle est basée sur le format ou la structure des données, notamment du texte, des images, de l’audio, de la vidéo, et des données structurées ou non structurées. Les exigences de sécurité et les procédures de traitement peuvent varier d'un format à l'autre.
7. Classification en fonction de l’emplacement : elle est basée sur l’emplacement physique ou géographique des données, par exemple les serveurs locaux, le stockage cloud ou les appareils mobiles. Cette classification permet aux entreprises de mettre en œuvre des mesures de sécurité et des contrôles d’accès aux données appropriés pour les différents sites.
8. Classification en fonction de la valeur : elle est basée sur la valeur des données pour l’entreprise, à savoir ressource de grande valeur, ressource de valeur moyenne ou ressource de faible valeur. Cette classification permet de hiérarchiser les mesures de sécurité et l’affectation des ressources.
La classification des données est essentielle pour se conformer aux exigences réglementaires, notamment le RGPD, l'HIPAA et PCI DSS, et pour protéger les informations sensibles contre les accès non autorisés, le vol ou l'utilisation abusive. Cela permet également aux entreprises de hiérarchiser leurs efforts de sécurité et d'allouer efficacement les ressources en fonction de l'importance des différents types de données.
Ressources

Démos produit
Personnalisez votre expérience de démo et découvrez notre sécurité et notre gestion des données en action.
30 jours d’essai gratuit
Utilisez le cloud pour sauvegarder, isoler vos données ou restaurer rapidement en cas de cybermenace ou de sinistre.
Rencontrez-nous
Rencontrez un spécialiste de la sécurité pour identifier vos risques et élaborer un plan de protection.
Loading