




Today’s enterprises are storing roughly double the amount of data every two years from before. They are using it for a variety of workloads such as development and testing, file shares, analytics, backup, cloud archival, etc. Enterprise data tends to get siloed into multiple storage products, which stores the data as multiple copies, replicated and uncompressed.
These redundancies, referred to as copy data, can easily be 10-20x more than the actual capacity needed. Providing that amount of storage requires large investments – not just on the storage side, but in the overall IT infrastructure, such as networking, archival, cloud bandwidth, manageability etc. Thus, there are significant cost advantages in reducing the data footprint.
Given Gartner’s prediction of 800% growth in enterprise data within the next five years, storage space efficiency capabilities, such as deduplication, are critical to any enterprise storage platform. A recent IDC survey suggests that 60% of the enterprise storage is used for copy data! This copy data sprawl is driven by the lack of a single system to consolidate secondary data. Copy data management is needed to reduce data duplication.To deal with the expected data growth, enterprises need storage products capable of delivering the highest level of space efficiency and capabilities — with optimal cost.
What is Data Deduplication
Deduplication is one of the key storage technologies enterprises rely on to deliver optimal storage efficiency and reduced infrastructure costs. Deduplication is one of the most valued storage technologies in enterprise storage products because it’s designed to eliminate the need to store multiple copies of identical files. This reduces the amount of storage capacity required to store any given amount of data. Deduplication is a space efficiency feature that can be found in many enterprise storage products. However, because of a lack of standards, the effectiveness of data reduction ratios and cost savings are difficult to quantify when comparing different vendors. There is simply not always an apples-to-apples comparison.
This is mainly because vendors may use different types of implementations and individual techniques that will produce different results. I think it’s safe to say that, now more than ever, having deduplication as one of the capabilities in a storage product has become more than just another checkbox. It’s crucial for enterprises to be educated about a product’s implementation details in order to understand the advertised deduplication ratios and cost savings.
Data Deduplication Challenges
Deduplication is the technology where duplicate blocks of data present in multiple files are identified and only the unique blocks are stored. This task relies on having a metadata database that stores fingerprints of the unique blocks, then used for comparisons when finding duplicates.
The deduplication task becomes quickly non-trivial when systems become large and complex. The metadata alone could go into terabytes, and hence can’t be handled by a single node. Also, it taxes the system resources as incoming data has to be parsed and compared with all the existing blocks.
Types of Deduplication
The value of deduplication is measured in a couple of ways:
- Effectiveness of data reduction capabilities and maximum achievable deduplication ratios.
- Overall impact on storage infrastructure cost and other data center resources and functions, such as network bandwidth, data replication, and disaster recovery requirements.
Certain deduplication traits can determine the level of data reduction efficiency and overall value based on the implementation details.
Fixed Length Deduplication
This dedupe algorithm divides data into fixed-size chunks. Once the blocks are compared, only the unique blocks are stored. When compared to the alternative, fixed-length is far less efficient, but easier to implement.
Variable Length Deduplication
This dedupe algorithm uses advanced context-aware anchor points to divide data into blocks based on the characteristics of the data itself and not on a fixed size. With fixed-length dedupe, small offsets in the data set can result in significant loss of space savings.
Local Deduplication
This approach limits data deduplication to just within a single node. There is no visibility to other nodes within the environment, where duplicate data will be found.
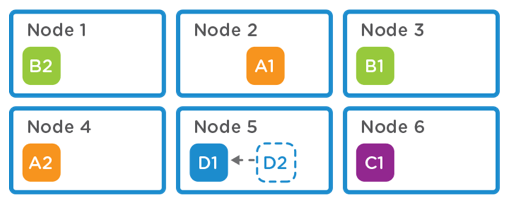
Node level deduplication only maintains a single copy of block D; D2 is a pointer to D1. No dedupe is achieved for blocks A & B.
Global Deduplication
This approach is the most effective process for data reduction and increases the dedupe ratio which helps to reduce the required capacity to store data. When a piece of data is written on one node, immediately after the write is acknowledged on node1, if the same data is written onto multiple additional nodes, the implementation is able to identify that data has already been written and will not write it again.
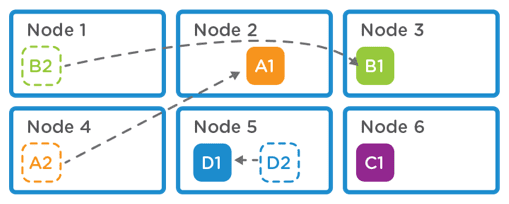
Cluster level deduplication only maintains a single copy of blocks A, B & D. A2, B2 & D2 are just pointers to A1, B1 & D1. This results in greater efficiencies in terms of utilization.
Integrated Data Compression
Compression works well on a single file, but across files, there is a need for some macro-level data compression. For example, when two identical copies of a file are stored, compression can individually compress the files. On the other hand, deduplication can completely eliminate the need to store any data for the second copy.
Adding compression to the deduped data you further reduce the data size. This works by finding small byte patterns common between the deduplicated blocks. Based on the type of data being ingested, compression can give no benefit for encrypted or random data, or up to 5-10x compression for common log files. Deduplication ratios for VMs, databases, file shares all lie somewhere in between that range.
How We Can Help
Our storage platform was designed from the ground up to provide a powerful and flexible global deduplication architecture. Cohesity utilizes a unique, variable-length data deduplication technology that spans an entire cluster, resulting in significant savings across the entire storage footprint.
With variable-length deduplication, the size is not fixed. Instead, the algorithm divides the data into chunks of varying sizes based on the data characteristics. The chunks are cut in a data dependent way that results in variable sized chunks and results in greater data reduction than fixed-size deduplication. The efficiency benefit of variable-length deduplication compounds over time, as additional backups are retained.
Cohesity’s global deduplication across all nodes in a cluster results in less storage consumed, compared with just node level deduplication used in several other backup and recovery solutions.
Deduplication is performed using a unique, variable-length data deduplication technology that spans an entire cluster, resulting in significant savings across a customer’s entire storage footprint. The figure below presents a logical illustration of the logic and functions performed as part of Cohesity’s global deduplication implementation.
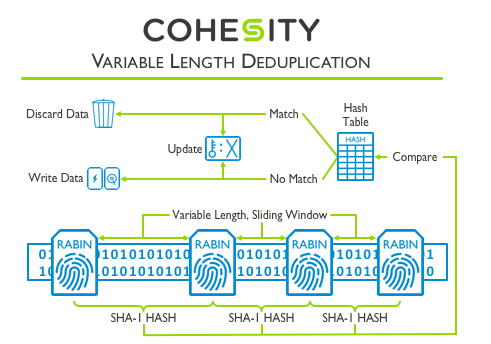
Cohesity SpanFS creates variable length chunks of data, which optimizes the level of deduplication no matter the type of file. In addition to providing global data deduplication, Cohesity allows customers to decide if their data should be deduplicated inline (when the data is written to the system), post-process (after the data is written to the system), or not at all.
This type of implementation is more complex and effective than a fixed length dedupe algorithm. It is worth highlighting that Cohesity’s global variable length deduplication implementation is implemented on a distributed system (scale out shared nothing cluster).
With this implementation, the dedupe algorithm inserts markers at variable intervals in order to maximize the ability to match data, regardless of the file system block size approach being used.
In-Line vs Post-Process Deduplication
Cohesity also allows the ability to decide when data should be deduplicated in-line (when the data is written to the system) or post-process dedupepost-process (after the data is written to the system) to optimize the backup protection jobs against backup time windows. Cohesity also provides compression of the deduped blocks to further maximize space efficiency.
Today, there aren’t many distributed storage systems with this type of implementation that are capable of delivering optimal data efficiency and cost in distributed storage systems.
– Enjoy
For future updates about Hyperconverged Secondary Storage, Cloud Computing, Networking, Storage, and anything in our wonderful world of technology be sure to follow me on Twitter: @PunchingClouds









%20%7C%20%E7%B6%99%E7%B6%9A%E7%9A%84%E3%83%87%E3%83%BC%E3%82%BF%E4%BF%9D%E8%AD%B7%20(CDP)%20%E3%81%A8%E3%81%AF%3F%20%7C%20%E7%94%A8%E8%AA%9E%E9%9B%86&_biz_n=0&rnd=759104&cdn_o=a&_biz_z=1751930137407)

